

LM Studio以llama.cpp为基础,是一个便于部署语言模型的框架,无需依赖性(dependencies)即可使用CPU或GPU进行加速,支援基于x86 CPU的AVX2指令集加速。透过AMD的Ryzen AI技术,使用者在x86笔记型电脑上运行LLM应用程式,如LM Studio,体验领先业界的效能。特别是对于记忆体速度高度敏感的LLM,AMD Ryzen AI展现出显著的效能优势。
对比测试中,尽管Intel笔记型电脑的RAM速度达8533 MT/s,优于AMD的7500 MT/s,AMD Ryzen AI 9 HX 375处理器在每秒token生成速度(tokens per second,LLM每秒生成并输出的单位,大致相当于萤幕显示的字数)方面仍然比竞争对手快出27%。




针对Meta Llama 3.2 1b Instruct(4-bit量化)模型,AMD Ryzen™ AI 9 HX 375处理器每秒生成速度达50.7 token。另一个效能指标「输出首个token的时间」(time to first token),则测量从提交提示(prompt)到模型开始生成token的延迟。测试显示,在大型模型中,AMD Ryzen AI HX 375处理器比同级竞争处理器速度快出高达3.5倍。
AMD Ryzen AI处理器中整合的三个加速器各有特定的工作负载专业化。基于XDNA 2架构的NPU在执行Copilot+工作负载时提供高效能和低功耗,而CPU则负责覆盖范围广泛的工具和框架相容性。内显(iGPU)则根据需求负责AI运算的加速。
LM Studio中提供的llama.cpp版本支援无厂商依赖性的Vulkan API,可根据硬体和驱动程式最佳化实现显著加速。与仅用CPU的模式相比,启用GPU offload后Meta Llama 3.2 1b Instruct模型的效能平均提升31%。对于较大模型Mistral Nemo 2407 12b Instruct,token生成阶段因频宽限制而平均提升5.1%。
在使用基于Vulkan的llama.cpp版本并启用GPU offload后,LM Studio中运行的模型整体效能显著提升。相比之下,Intel Core Ultra 7 258v处理器在LM Studio中未达同等效能。因此,为确保测试公平性,此组比较未将Intel处理器的GPU-offload效能纳入评比。
AMD Ryzen AI 300系列处理器包含可变显示记忆体(VGM)功能,可将512 MB的专用记忆空间扩展至高达系统RAM容量的75%,对于记忆体敏感的应用程式提供连续的记忆体支援。在启用VGM(16GB)模式下,Meta Llama 3.2 1b Instruct模型的效能提升达22%,而整体速度相比传统CPU模式增长60%。此外,对于Mistral Nemo 2407 12b Instruct等大型模型,iGPU加速结合VGM模式后效能可提升17%。
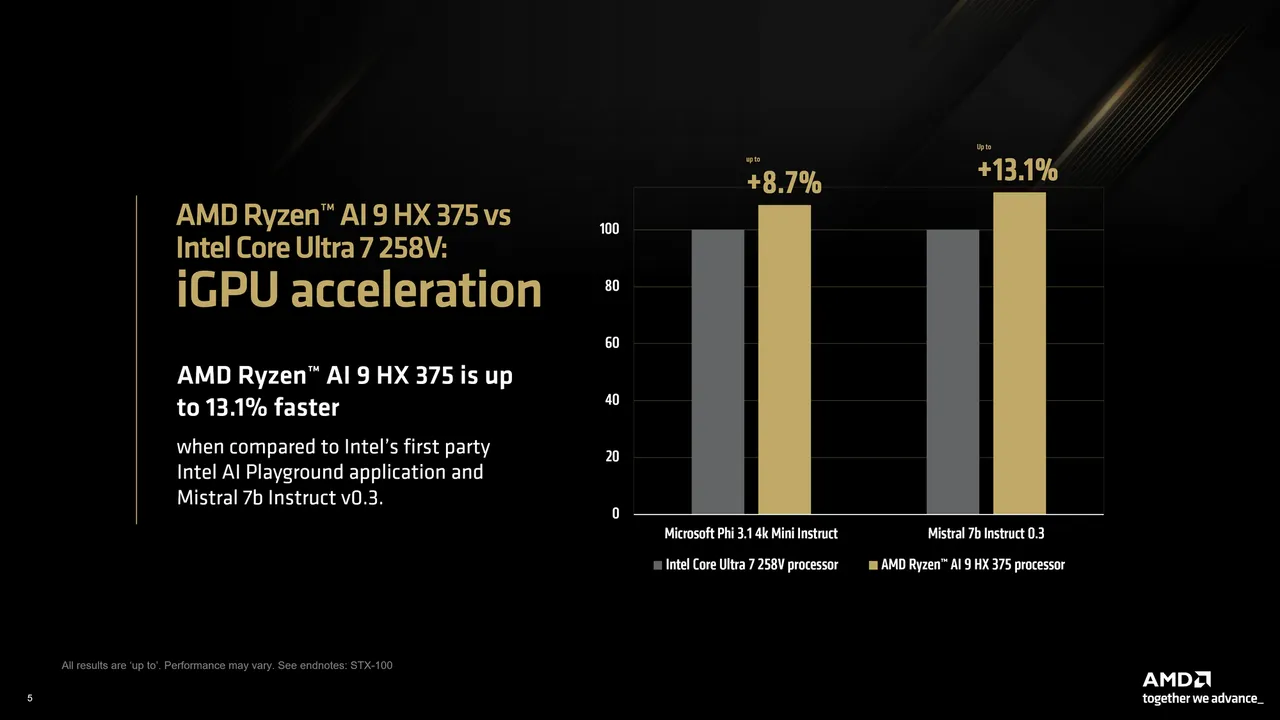
为进一步比较Intel平台效能,我们在Intel AI Playground应用程式(基于IPEX-LLM和LangChain)中测试了Mistral 7b Instruct v0.3和Microsoft Phi 3.1 Mini Instruct模型。结果显示,经过量化后的AMD Ryzen AI 9 HX 375处理器在Phi 3.1模型上的生成速度比竞争对手快8.7%,而在Mistral 7b Instruct 0.3模型上则快13%。
 點擊閱讀下一則新聞
點擊閱讀下一則新聞




